In this article I will show how to use LangGraph to create an AI agent that works with multiple local LLMs. Through a simple example I will implement a news agent that loads a rss feed and provides short news summaries and categorization of the stories.
Agent
First of all, what is an Agent?
Simply put, an agent is basically an application that implements some sort of workflow where “regular” application code interacts with an AI (often an LLM) to solve a task or a series of tasks. An example of a common agent task is combining an LLM with api endpoints to pull in external information to expand the knowledge base of the LLM to include current events.
LangGraph
In this article I decided to use LangGraph to implement my own agent from scratch. When implementing agents, you can think of LangGraph as an orchestration layer that allows you to model tasks as nodes in a graph. Each node represents a task that is connected to a subsequent task through an edge in the graph.
The first step is identifying how to break your problem into tasks that can be translated into nodes and edges in the graph. Nodes are just like functions, so you can make them as broad or granular as you want. In the screenshot below I have added a visual representation of the nodes I configured for my news agent.
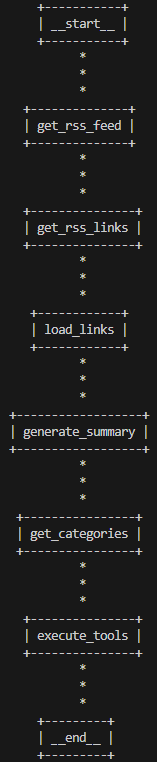
Wiring up the graph nodes in LangGraph is straightforward. All you need to do is call the add_node function to name a particular node and provide an execution step in the form of a method. Next you use the add_edge function to connect the nodes in the order you want them to be executed. I have included the relevant code below:
One convenient thing about LangGraph’s state management is that the result of each state is automatically passed to the next node through the GraphState object.
I consider the first three tasks (i.e. get_rss_feed, get_rss_links and load_links) to be setup tasks where I gather up the full content of the news articles from the links in the rss feed. Next, we have the tasks generate_summary and get_categories where I incorporate two different LLMs.
generate_summary
In the generate_summary node I am feeding the full text of the news article to the LLM and asking it to provide a 2 paragraph summary of the text. Which LLM to use is flexible, but in this case, I decided to go with the 1B version of llama 3.2.
I have included the relevant node code below:
I am using Ollama as the hosting environment. Check out the code below for an example of how to configure an instance of Llama 3.2 in Ollama.
Notice how I am setting num_ctx to increase the context window of the prompt. The default is 2048, which proved to be too small for many news articles.
get_categories
The LLM integration in the generate_summary node is based solely on prompting and RAG. In the get_categories node I extended this by configuring a new LLM with support for tool calling. You can think of tool calling as a concept in LLMs that enables the LLM to interact with external tools like a regular Python method.
For this node I decided to us qwen 2.5 as the LLM, but before we can call tools, the first step is to register one or more tools with the LLM as seen in the code below:
Next let’s take a look at the code behind the get_categories node:
How are tool functions executed?
One key feature of tool calling is that the LLM won’t execute the tool directly. Instead, the LLM will just generate a textual representation of a function call based on the schema of the registered tool function. Post inference the agent code will parse the tool call string and make a call to the appropriate function using dynamic code.
Based on the schema defined for the get_article_categories tool, Qwen 2.5 will generate a tool call string in the format seen below:
The string above can then be parsed and executed as code in the final node called execute_tools in the LangGraph workflow. I have included the code below:
As you can see, the code in the graph node will parse the details of the function call and dynamically execute the function. In this simple example I have instructed the LLM to determine the category of the news article based on the previously generated summary. The inferred categories are then passed on to the tool function for further processing.
One of the key benefits of tool calling is that you can take advantage of the LLM’s language abilities to extract relevant information from the RAG prompt and populate the input arguments. As I mentioned earlier, a common use case for this is making external calls from the tool function. However, the explicit contract of the tool response is also useful for programmatic integration of the LLM with code in general. Regular prompting leaves the format of the response a little bit open ended, but the tool call follows a predictable schema.
Observations
I was quite happy with the performance of the news agent, but it should technically be unnecessary to use two different LLMs to implement this. However, I noticed that these small local models sometimes have a difficult time switching between tool calling and regular prompting. As a result, I would sometimes get a combination of both in the responses, but I suspect this is a feature of these smaller models. Some more info here to support that.
I have uploaded the code to Github in case you are interested in checking it out.